Web search engine that consists mainly of four parts: a web crawler, an indexer, a built-in database engine and the p2p index exchange protocol, based on HTTP. #Web search engine #Web crawler #Built-in database engine #Web search #Engine #Web
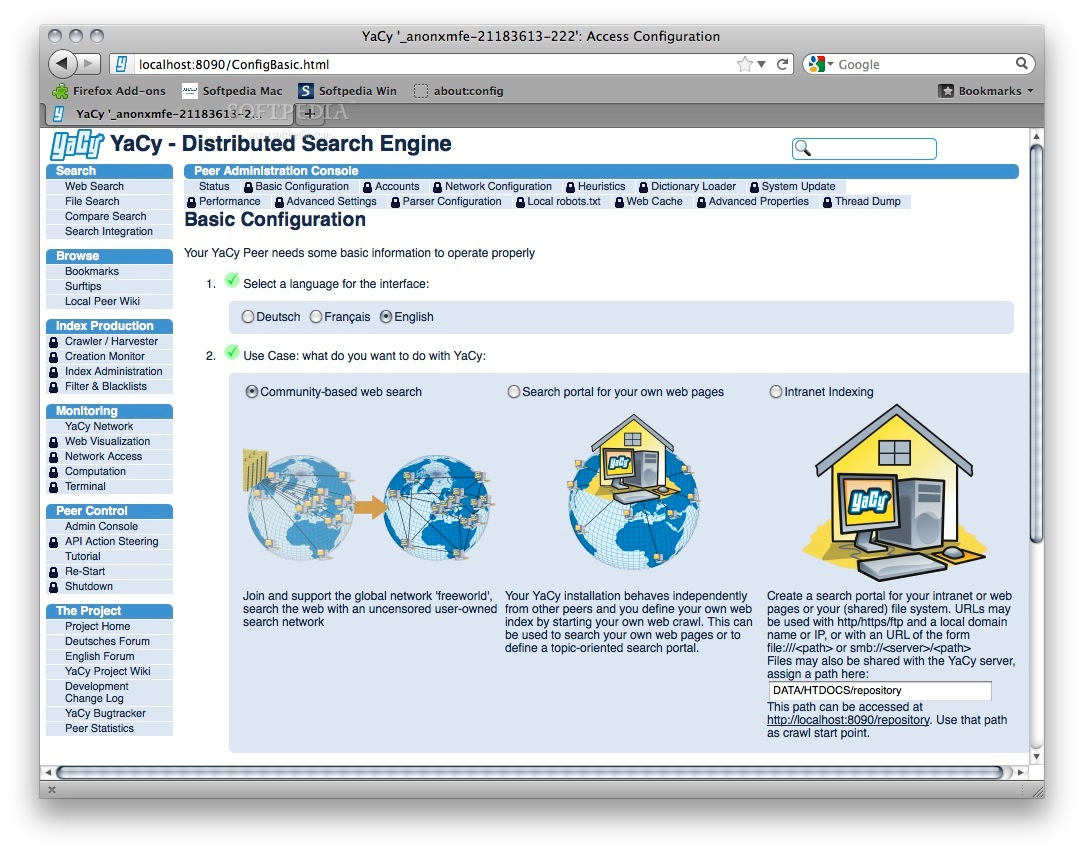
The YaCy search engine may be accessed through the built-in http server. All parts of this architecture are included in the YaCy distribution.
YaCy has a built-in HTTP server, and the user interface is realized as web pages on the own web server. A search request to YaCy is done inside your web browser.
A web search engine can only search web pages that had been crawled, which means that all pages of subpages (and so on) of a start point had been loaded. YaCy has an integrated web crawler.
Before a huge number of web pages can be searched efficiently, the pages must be indexed. This is a very difficult process which runs inside YaCy without any user action. After indexing of web pages a single YaCy installation is able to provide search results from more that 10 million of web pages efficiently.
Installation: Just decompress the archive and run the start script, then open http://localhost:8080.
System requirements
YaCy 1.82
add to watchlist add to download basket send us an update REPORT- runs on:
- Mac OS X (PPC & Intel)
- file size:
- 45.2 MB
- filename:
- yacy_v1.82_20150121_9000.dmg
- main category:
- Internet Utilities
- developer:
- visit homepage
Windows Sandbox Launcher

4k Video Downloader

IrfanView

Zoom Client

Bitdefender Antivirus Free

7-Zip

Microsoft Teams

ShareX

calibre

Context Menu Manager

- ShareX
- calibre
- Context Menu Manager
- Windows Sandbox Launcher
- 4k Video Downloader
- IrfanView
- Zoom Client
- Bitdefender Antivirus Free
- 7-Zip
- Microsoft Teams