A modern C++ library with a focus on portability and application correctness with a platform abstraction layer for common tasks.. #C++ library #Create GUI #Interface network service #Library #Layer #C++
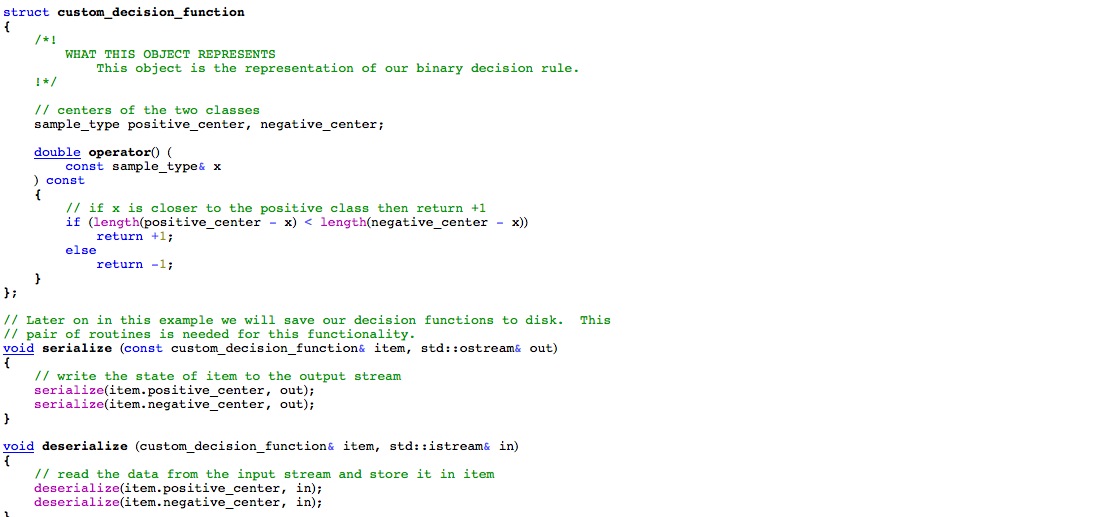
dlib is a powerful library that has a large focus on portability as well as application correctness.
Also, dlib includes a platform abstraction layer for common tasks such as interfacing with network services, handling threads, or creating graphical user interfaces.
NOTE: dlib is licensed and distributed under the terms of the Boost Software License (BSL1.0).
What's new in dlib 18.18:
- New Features:
- Added the set_ptrm() routine for assigning dlib::matrix objects to arbitrary memory blocks.
- Bug fixes:
dlib 18.18
add to watchlist add to download basket send us an update REPORT- runs on:
- Mac OS X (-)
- file size:
- 11.1 MB
- filename:
- dlib-18.18.zip
1 screenshot:
- main category:
- Development
- developer:
- visit homepage
4k Video Downloader
Export your favorite YouTube videos and playlists with this intuitive, lightweight program, built to facilitate downloading clips from the popular website

Zoom Client
The official desktop client for Zoom, the popular video conferencing and collaboration tool used by millions of people worldwide

7-Zip
An intuitive application with a very good compression ratio that can help you not only create and extract archives, but also test them for errors

ShareX
Capture your screen, create GIFs, and record videos through this versatile solution that includes various other amenities: an OCR scanner, image uploader, URL shortener, and much more

Microsoft Teams
Effortlessly chat, collaborate on projects, and transfer files within a business-like environment by employing this Microsoft-vetted application

IrfanView
With support for a long list of plugins, this minimalistic utility helps you view images, as well as edit and convert them using a built-in batch mode

paint.net
Packed with an array of options and an intuitive interface, this application enables you to create professional-looking photographs

Bitdefender Antivirus Free
Feather-light and free antivirus solution from renowned developer that keeps the PC protected at all times from malware without requiring user configuration

Windows Sandbox Launcher
Set up the Windows Sandbox parameters to your specific requirements, with this dedicated launcher that features advanced parametrization

calibre
Effortlessly keep your e-book library thoroughly organized with the help of the numerous features offered by this efficient and capable manager

38% discount
Bitdefender Antivirus Free
- Bitdefender Antivirus Free
- Windows Sandbox Launcher
- calibre
- 4k Video Downloader
- Zoom Client
- 7-Zip
- ShareX
- Microsoft Teams
- IrfanView
- paint.net
essentials
User Comments
This enables Disqus, Inc. to process some of your data. Disqus privacy policy